R² = 0,75 → le modèle explique 75% de la variabilité de Y
Interpréter R²
R²
Interprétation
< 0,3
Modèle faible
0,3 - 0,6
Modèle moyen
0,6 - 0,8
Bon modèle
> 0,8
Excellent modèle
Note
En SHS, un R² de 0,3-0,5 n’est pas rare.
Mise en pratique avec R
Représentater le modèle avec R
Essayons tout d’abord de représenter un modèle !
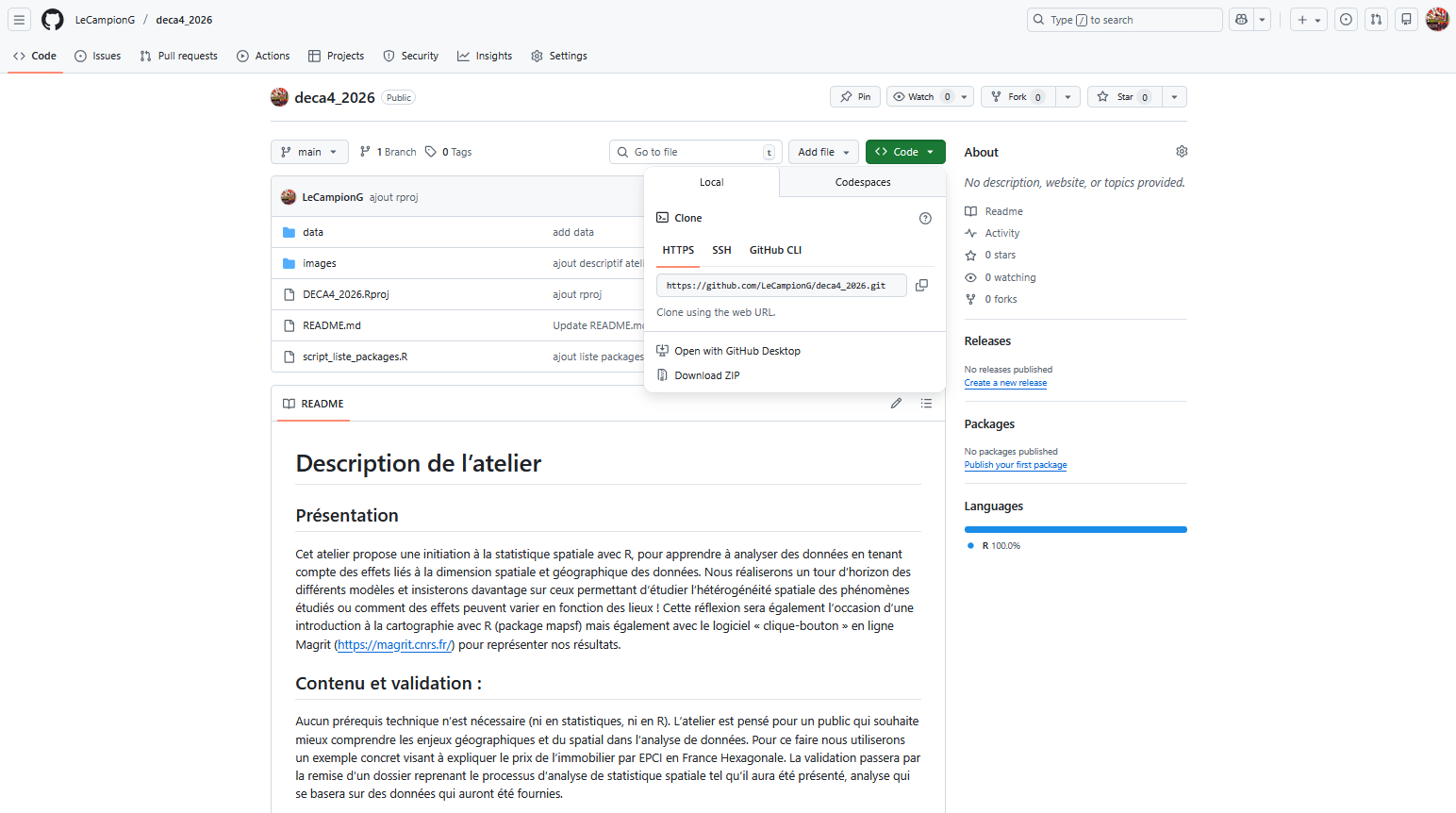
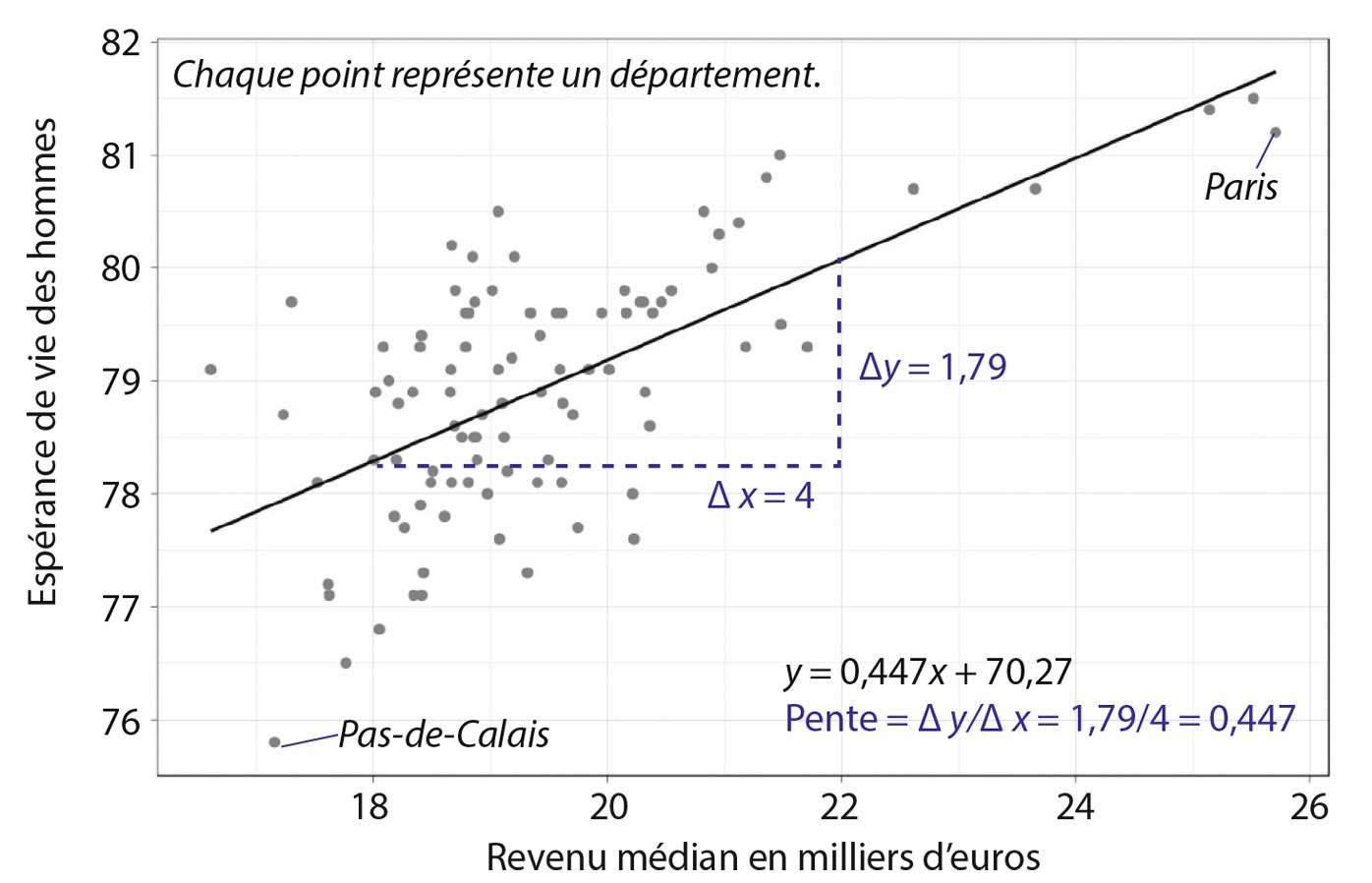
Nous cherchons à expliquer le prix median de l’immobilier par le niveau de vie médian des menages par EPCI :
library(ggplot2)plot1 <-ggplot(immo_df, aes(x = med_niveau_vis, y = prix_med)) +geom_point() +labs(title ="Relation prix median au m² vs niveau de vie median par EPCI") +xlab("niveau de vie median par EPCI (€)") +ylab("Prix median au m² (€)")+theme(plot.title =element_text(face ="bold"))plot1 +geom_point(col="blue") +geom_smooth(method ="lm", color="red", se=TRUE) +theme_grey()
Représentater le modèle avec R 2
Une autre manière de faire qui peut s’avérer pratique…
library(car)car::scatterplot(prix_med ~ med_niveau_vis, data = immo_df, id =list(n=10))
[1] 36 63 75 180 266 507 717 927 1133 1139
Créer le modèle statistique
Produire un modèle de régression rien de plus simple !
# Estimation du modèle avec la fonction lm (pour linear model)lm1 <-lm(data = immo_df, formula = prix_med ~ med_niveau_vis)summary(lm1)
Call:
lm(formula = prix_med ~ med_niveau_vis, data = immo_df)
Residuals:
Min 1Q Median 3Q Max
-1717.4 -374.0 -147.5 172.0 8888.1
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1590.85 19.22 82.77 <2e-16 ***
med_niveau_vis 485.91 19.21 25.30 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 672.2 on 1221 degrees of freedom
Multiple R-squared: 0.3439, Adjusted R-squared: 0.3434
F-statistic: 640 on 1 and 1221 DF, p-value: < 2.2e-16
Premiers résultats
La fonction summary() présente les estimations de façon brute, mais d’autres fonctions permettent des rendus plus esthétiques, comme avec le package gtsummary :
library(gtsummary)# En tableaugtsummary::tbl_regression(lm1)
Characteristic
Beta
95% CI
p-value
med_niveau_vis
486
448, 524
<0.001
Abbreviation: CI = Confidence Interval
Condition de réalisation d’une régression
Les hypothèses de la régression classique
Linéarité : relation linéaire entre Y et X
Indépendance : les observations sont indépendantes
Homoscédasticité : variance constante des résidus
Normalité : distribution normale des résidus
Pas d’autocorrélation : les résidus ne doivent pas être auto-corrélés
Non-colinéarité : les variables explicatives ne sont pas trop corrélées
Limites de la régression classique (1/2)
Hypothèse d’indépendance des observations
En géographie, cette hypothèse est souvent violée :
Les phénomènes spatiaux sont rarement indépendants : on parle de la dépendance spatiale : autocorrélation des résidus.
“Tout est lié à tout, mais les choses proches sont plus liées que les choses éloignées” (Tobler, 1970)
Limites de la régression classique (2/2)
Hypothèse de stationnarité
La régression classique suppose des coefficients constants dans l’espace :
L’effet d’une variable est le même partout
Pas de prise en compte des variations locales
Inadapté pour des phénomènes géographiques hétérogènes et plus largement en SHS
Diagnostiquer la régression avec R
On complexifie notre modèle
Attention
Avant de lancer ce modèle des conditions d’applications doivent être vérifiées!
# Distribution de la variable dépendante :hist(immo_df$prix_med, freq=FALSE, breaks =35, col ="darkblue", border ="white", main ="Prix median au m² par EPCI")
La VIF (Variance Inflation Factor) est une très bonne méthode pour vérifier les risques de multicolinéarité. Elle suppose simplement d’avoir estimé un premier modèle pour être utilisée.
# On peut aussi directement l'ajouter au résumé des coefficient obtenu avec gtsummarylibrary(gtsummary)mod.lm %>%tbl_regression(intercept =TRUE) %>%add_vif()
Characteristic
Beta
95% CI
p-value
VIF
(Intercept)
1,593
1,571, 1,615
<0.001
perc_log_vac
-287
-315, -260
<0.001
1.6
perc_maison
-128
-168, -89
<0.001
3.2
perc_tiny_log
-262
-316, -207
<0.001
6.2
dens_pop
174
144, 204
<0.001
1.9
med_niveau_vis
288
261, 315
<0.001
1.5
part_log_suroccup
389
335, 443
<0.001
6.0
part_agri_nb_emploi
-21
-50, 8.8
0.2
1.8
part_cadre_profintellec_nbemploi
-7.8
-47, 31
0.7
3.2
Abbreviations: CI = Confidence Interval, VIF = Variance Inflation Factor
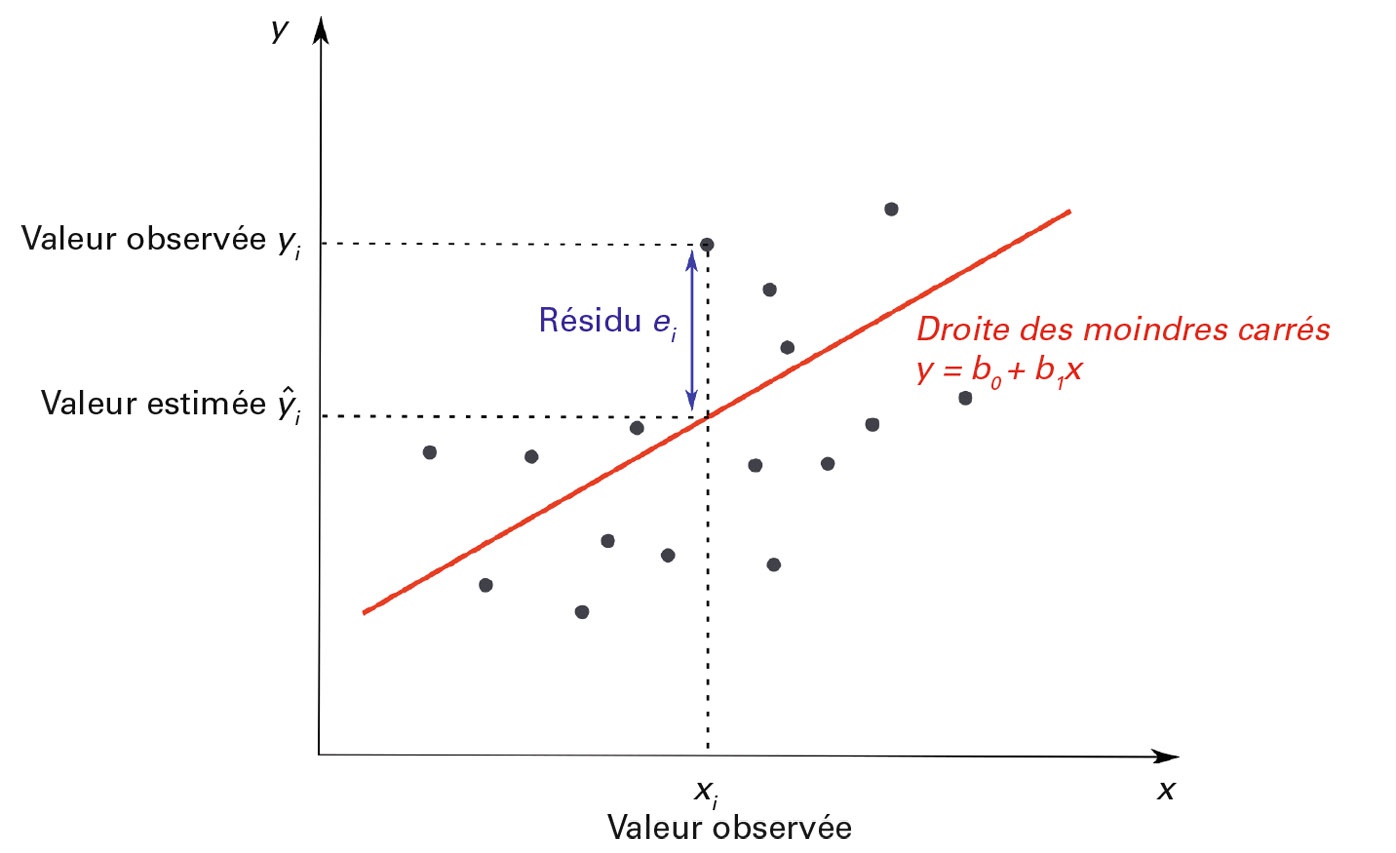
Analyse des résidus
Notes
L’analyse des résidus est très importante car les conditions de validité d’un modèle linéaire au delà des résultats repose grandement sur les résidus. Ils permettent en outre d’identifier les individus extrêmes (ou outliers).
par(mfrow=c(1,3))plot(rstudent(mod.lm))hist(rstudent(mod.lm), breaks =20, col="darkblue", border="white", main="Analyse visuelle des résidus")qqPlot(mod.lm)
[1] 36 266
Analyse des résidus 2
Si la voie graphique ne vous inspire pas il existe des tests statistiques qui permettent de vérifier la normalité des résidus ou bien leur homoscédasticité.
Ils ont cela de particulier qu’ici nous cherchons à accepter H0 et donc pour valider la normalité ou l’homoscédasticité il faut que \(p−value>0.05\)
# Pour étudier la normalité on peut utiliser le test de Shapiro-Wilkshapiro.test(mod.lm$residuals)
Shapiro-Wilk normality test
data: mod.lm$residuals
W = 0.90792, p-value < 2.2e-16
# Pour évaluer l'homoscédasticité on peut utiliser le test de Breusch-Pagan. Le package car propose une fonction pour le réaliserncvTest(mod.lm)
Non-constant Variance Score Test
Variance formula: ~ fitted.values
Chisquare = 1151.844, Df = 1, p = < 2.22e-16
Outliers
Aparte
La question des outliers (ou individus extrême) est très importante ! Un seul individu de par son côté extrême pourra faire varier voire fausser complétement notre test.
Les données spatiales ont des propriétés particulières :
Position : les observations ont une localisation
Dépendance spatiale : proximité = similitude
Hétérogénéité spatiale : les processus varient dans l’espace
Les deux problèmes fondamentaux
1. Autocorrélation spatiale
Les observations voisines se ressemblent
Conséquence : violation de l’hypothèse d’indépendance
2. Non-stationnarité spatiale
Les relations varient dans l’espace
Conséquence : coefficients non constants
Comment la statistique spatiale répond
Pour l’autocorrélation :
Mesurer et tester l’autocorrélation spatiale
Modèles spatiaux (SAR, SEM, etc.)
Pour la non-stationnarité :
Régressions géographiquement pondérées (GWR)
Modèles locaux
Préparation des données en vue de la stat spatiale !
La jointure
# l'option all.x = TRUE permet de garder toutes les lignes de epci_sf,# même celles qui n'ont pas de correspondance dans immo_dfdata_immo <-merge(x = epci_sf, y = immo_df, by.x ="CODE_SIREN", by.y ="SIREN", all.x =TRUE)nrow(immo_df)
[1] 1223
nrow(epci_sf)
[1] 1242
nrow(data_immo)
[1] 1242
Représenter
mf_map(x = data_immo)mf_map(x = data_immo[is.na(data_immo$prix_med),], col ='red', add =TRUE)
# Pour exporter # st_write(data_immo, "data_immo.gpkg", driver = "GPKG")
La carte du prix de l’immobilier
# La palette de couleurs :cols_v1 <-c("#08519c", "#3182bd", "#6baed6", "#9ecae1", "#c6dbef", "#eff3ff", "#ffffce", "#fee5d9", "#fcbba1", "#fc9272", "#fb6a4a", "#de2d26")# Carte du prix médian mf_map(x = data_immo, var ="prix_med", type ="choro", border ="#ebebeb", lwd =0.1, breaks=quantile(data_immo$prix_med,seq(0,1, by=1/11)), pal=cols_v1, leg_title ="Prix médian", leg_val_rnd =1)mf_title("Prix Médian du logement par EPCI France Métropolitaine") #titre
La carte des résidus… ou montrer la structure spatiale
data_immo$res_reg <- mod.lm$residuals# Définition d'une palette de couleurcols_v1 <-c("#08519c", "#3182bd", "#6baed6", "#9ecae1", "#c6dbef", "#eff3ff", "#ffffce", "#fee5d9", "#fcbba1", "#fc9272", "#fb6a4a", "#de2d26")# Réalisation de la cartemf_map(x = data_immo, var ="res_reg", type ="choro", border ="#ebebeb", lwd =0.1, breaks=quantile(data_immo$res_reg,seq(0,1, by=1/11)), pal=cols_v1, leg_title ="Résidus de régression\nlinéaire 'classique'", leg_val_rnd =1)mf_title("Résidus modèle lm") #titre
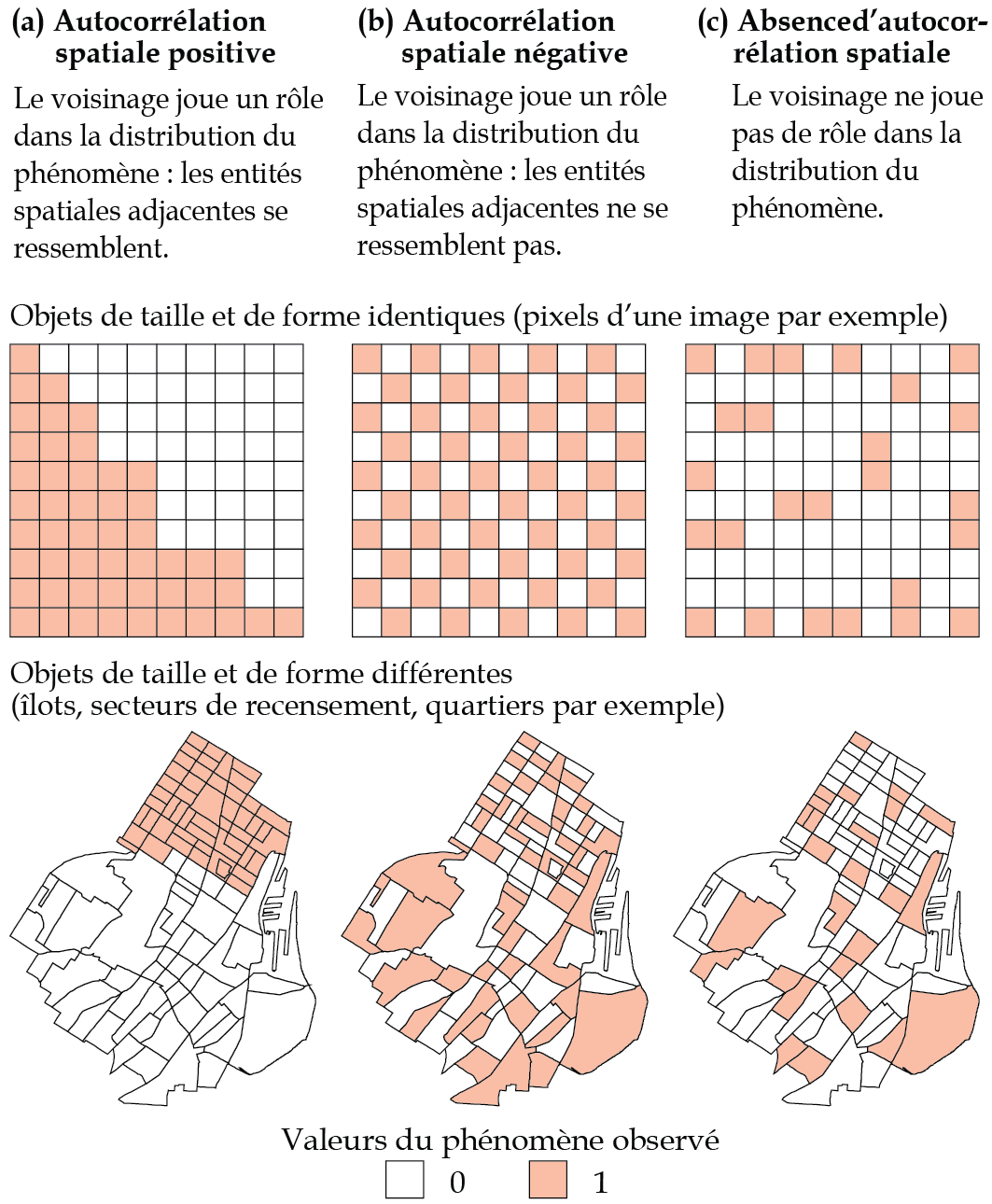
L’Autocorrélation Spatiale
Définition
L’autocorrélation spatiale mesure la similitude entre observations voisines :
Positive : les valeurs similaires sont proches
Négative : les valeurs dissimilaires sont proches
Nulle : distribution aléatoire dans l’espace
Représentation
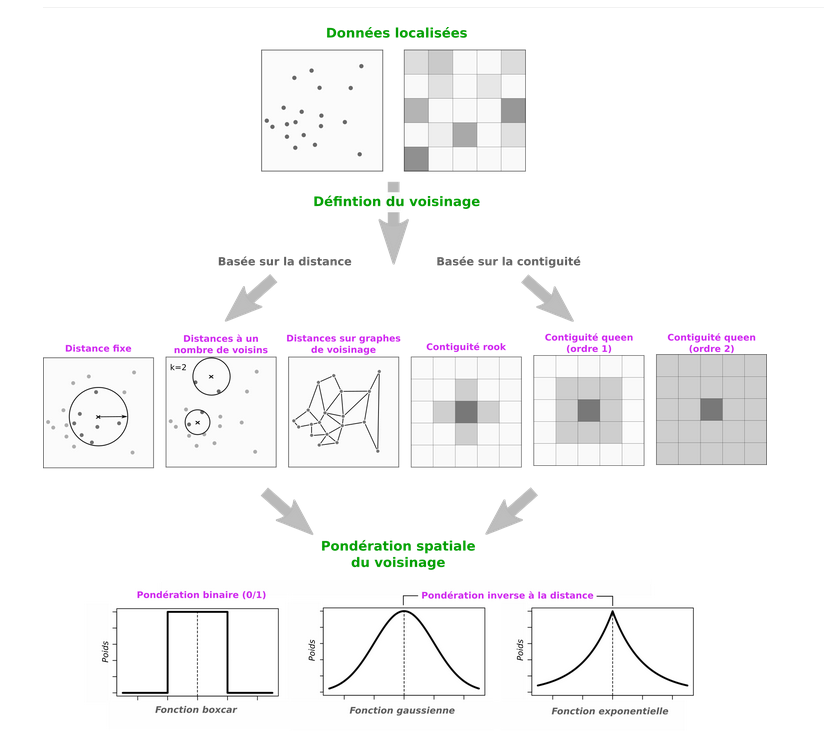
La matrice de poids spatiaux (1/2)
Pour mesurer l’autocorrélation, il faut définir le voisinage :
Matrice W : qui est voisin de qui ?
\(w_{ij} = 1\) si i et j sont voisins
\(w_{ij} = 0\) sinon
La matrice de poids spatiaux (2/2)
Différentes définitions du voisinage
Voisinage avec R
library(spdep)# Création de la liste des voisins : avec l'option queen = TRUE, # sont considérés comme voisins 2 polygones possédant au moins 1 sommet commun#help(poly2nb)neighbours_epci <-poly2nb(data_immo, queen =TRUE) # cette opération se fait aussi avec un objet sp #shape_nbq <- poly2nb(shape, queen = TRUE)# Obtention des coordonnées des centroïdes#coord<-coordinates(shape)coord <-st_coordinates(st_centroid(data_immo))# Faire un graphe de voisinageplot(neighbours_epci, coord)
# si on prend le 1er élément de neighbours_epci, on voit qu'il a pour voisins les polygones 62, 74 etc.neighbours_epci[[1]]
[1] 62 74 338 1135 1136 1137 1140
# ce qu'on peut vérifier sur la carte :neighbours1 <- data_immo[c(1,62,74,338,1135,1136,1137,1140),]neighbours1$index <-rownames(neighbours1)mf_map(x = neighbours1)mf_label(x = neighbours1, var ="index")
Création de la matrice de voisinage
# la fonction nb2listw attribue des poids à chaque voisin# par ex. si un polygone a 4 voisins, ils auront chacun un poids de 1/4 = 0.25#help("nb2listw")neighbours_epci_w <-nb2listw(neighbours_epci)# les poids sont stockés dans le 3ème élément de neighbours_epci_w# par ex. si on veut connaître les poids des voisins du 1er élément :neighbours_epci_w[[3]][1]
Comment faire si l’on a un polygone sans voisins ? Sur le plan technique, la fonction nb2listw prévoit ce cas de figure. Il faut utiliser l’argument zero.policy est indiquer TRUE. Au niveau théorique, c’est moins clair. De manière générale les indices d’autocorrélation spatiale et autres régressions spatiales ont été conçus en partant du principe que les entités spatiales avaient un voisinage. Ceci dit il n’y a pas à ma connaissance de règles qui obligent à les supprimer ou intégrer, ni de consensus scientifique sur l’approche à adopter.
# La palette de couleurs :cols_v1 <-c("#08519c", "#3182bd", "#6baed6", "#9ecae1", "#c6dbef", "#eff3ff", "#ffffce", "#fee5d9", "#fcbba1", "#fc9272", "#fb6a4a", "#de2d26")# Carte du prix médian mf_map(x = data_immo, var ="prix_med", type ="choro", border ="#ebebeb", lwd =0.1, breaks=quantile(data_immo$prix_med,seq(0,1, by=1/11)), pal=cols_v1, leg_title ="Prix médian", leg_val_rnd =1)mf_title("Prix Médian du logement par EPCI France Métropolitaine") #titre
Moran avec R
library(spdep)# Pour l'occasion on va standardiser notre prix médian. # Cela permettra par la suite de le comparer à d'autres variables si d'autres analyses d'autocorrélation spatiale sont réaliséesdata_immo$prix_med_z <- (data_immo$prix_med-mean(data_immo$prix_med))/sd(data_immo$prix_med)# Test de Moran :# On indique dans un premier temps la variable que l'on souhaite analyser# Puis la matrice de voisinage# L'argument zero.policy=TRUE permet de préciser que l'on souhaite intégrer à l'analyse les entités spatiales qui n'auraient pas de voisins# L'argument randomisation=FALSE transmet à la fonction que nous supposons que la distribution est normale. Dans le cas contraire on devrait partir sur une solution de type Monte-Carlo qui repose sur la randomisationmoran.test(data_immo$prix_med_z, neighbours_epci_w, zero.policy =TRUE, randomisation =FALSE)
Moran I test under normality
data: data_immo$prix_med_z
weights: neighbours_epci_w
Moran I statistic standard deviate = 41.143, p-value < 2.2e-16
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.7154340217 -0.0008183306 0.0003030652
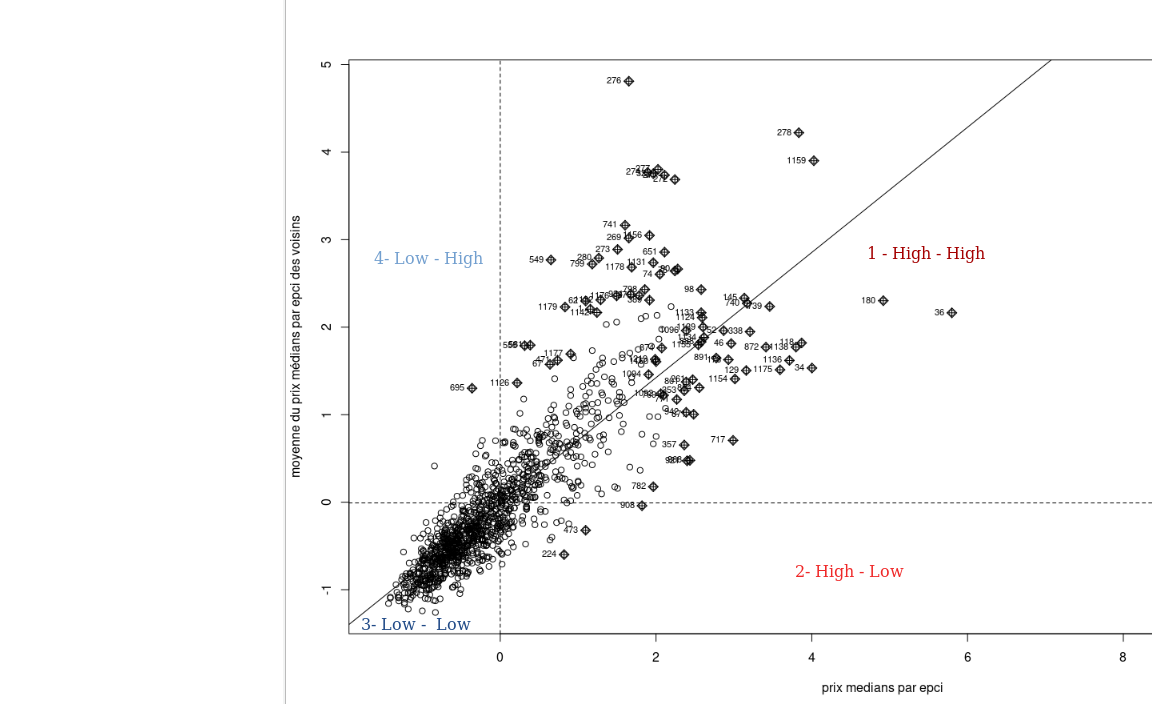
moran.plot(data_immo$prix_med_z,neighbours_epci_w, labels =TRUE, xlab="prix medians par epci", ylab="moyenne du prix médians par epci des voisins")
Mesure la contribution locale à l’autocorrélation globale
Types de clusters (1/2)
Hot spots (HH)
Valeur élevée entourée de valeurs élevées
Cold spots (LL)
Valeur faible entourée de valeurs faibles
Outliers (HL)
Valeur élevée entourée de valeurs faibles
Outliers (LH)
Valeur faible entourée de valeurs élevées
Types de clusters (2/2)
Interprétation des LISA
Utilité :
Identifier des zones homogènes
Détecter des anomalies spatiales
Guider les politiques locales
Compléter l’analyse globale
Attention : tenir compte des tests de significativité !
LISA avec R
library(rgeoda)# Pour utiliser la fonction local_moran proposée par le package rgeoda 2 pré-requis:# 1- utiliser la fonction queen_weights du package rgeoda pour calculer une matrice de contiguïté de type queen queen_w <-queen_weights(data_immo)# 2- Sortir la variable à étudier dans un vecteurprix_med_z = data_immo["prix_med_z"]lisa <-local_moran(queen_w, prix_med_z)# Pour visualiser les résultats des LISA il faut les stocker dans des objets ou dans les base de données pour les représenter lisa_colors <-lisa_colors(lisa)lisa_labels <-lisa_labels(lisa)lisa_clusters <-lisa_clusters(lisa)lisa_value <-lisa_values(lisa)lisa_pvalue<-lisa_pvalues(lisa)# Carte de Moran locauxdata_immo$moranlocalvalue <-lisa_values(lisa)cols_v2 <-c("#08519c", "#3182bd", "#6baed6", "#9ecae1", "#c6dbef", "#eff3ff", "#ffffce", "#fee5d9", "#fcbba1", "#fc9272", "#fb6a4a", "#de2d26")mf_map(x = data_immo, var ="moranlocalvalue", type ="choro", border ="#ebebeb", lwd =0.1, pal=cols_v2, leg_title ="Local Moran", leg_val_rnd =1)mf_title("Carte des LISA du prix médian du logement")
# Carte des p-value des moran locauxdata_immo$moranlocalpvalue<-lisa_pvalues(lisa)library(dplyr)# Pour plus de lisibilité dans la carte on va faire des classes des p-valuedata_immo<- data_immo %>%mutate(lisapvalue_fac =case_when(moranlocalpvalue <=0.002~"[0.001;0.002[", moranlocalpvalue <=0.01~"[0.002;0.01[", moranlocalpvalue <=0.05~"[0.01;0.05[",TRUE~"[0.05;0.5]")) %>%mutate(lisapvalue_fac =factor(lisapvalue_fac,levels =c("[0.001;0.002[", "[0.002;0.01[","[0.01;0.05[","[0.05;0.5]")))mypal <-mf_get_pal(n =4, palette ="Reds")mf_map(x = data_immo, var ="lisapvalue_fac", type ="typo", border ="grey3", lwd =0.1, pal=mypal, leg_title ="P-value Local Moran")mf_title("Carte des significativité des LISA")
# Carte des clusters lisa avec rgeodaplot(st_geometry(data_immo), col=sapply(lisa_clusters, function(x){return(lisa_colors[[x+1]])}), border ="#333333", lwd=0.2)title(main ="Cluster LISA")legend('bottomleft', legend = lisa_labels, fill = lisa_colors, border ="#eeeeee")
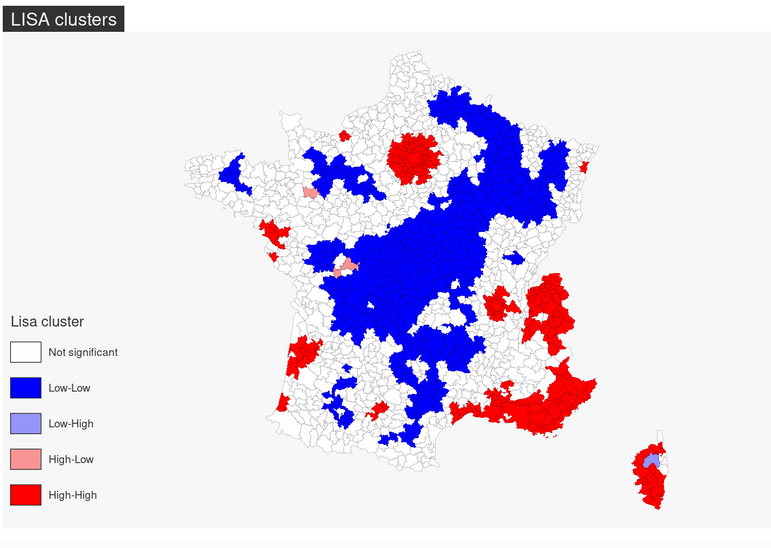
# En utilisant le package mapsfdata_immo$testmoran <-sapply(lisa_clusters, function(x){return(lisa_labels[[x+1]])})colors <-c("white","blue",rgb(0,0,1,alpha=0.4),rgb(1,0,0,alpha=0.4),"red")mf_map(x = data_immo, var ="testmoran", type ="typo", border ="black", lwd =0.1, pal= colors,val_order =c("Not significant","Low-Low","Low-High","High-Low","High-High"),leg_title ="Lisa cluster")mf_title("LISA clusters")
L’Hétérogénéité Spatiale
Le problème de la non-stationnarité
Dans une régression classique, les coefficients sont constants :
Plus on s’éloigne de i, moins le poids est important
Le paramètre clé : bandwidth
Le bandwidth (b) détermine la taille du voisinage :
b petit : forte variation locale, risque de sur-ajustement
b grand : lissage, se rapproche du modèle global
b optimal : minimise un critère (AICc, CV)
Sélection automatique du bandwidth
Critère AICc (Akaike Information Criterion corrigé) :
Compromis ajustement / complexité
Correction pour petits échantillons
Sélection automatique possible
Cross-validation :
Validation croisée
Erreur de prédiction
Produire une GWR avec R
Pour réaliser une GWR sur R plusieurs packages reconnus existent. On peut citer notamment le package spgwret le package GWmodel. Nous choisirons d’utiliser ici le package GWmodel.
Note
Attention, les fonctions de ce package ne sont pas utilisables sur des objets de type sf, il faut travailler sur des objets de type Spatial DataFrame (SpatialPointsDataFrame or SpatialPolygonsDataFrame) (contrairement à spgwr qui peut travailler avec un format sf).
La première étape est de calculer la distance entre toutes nos observations. Pour ce faire nous utiliserons la fonction gw.dist().
library(GWmodel)# Pour construire la matrice de distances entre centroïdes des EPCI :dm.calib <-gw.dist(dp.locat =coordinates(sp_data_immo))
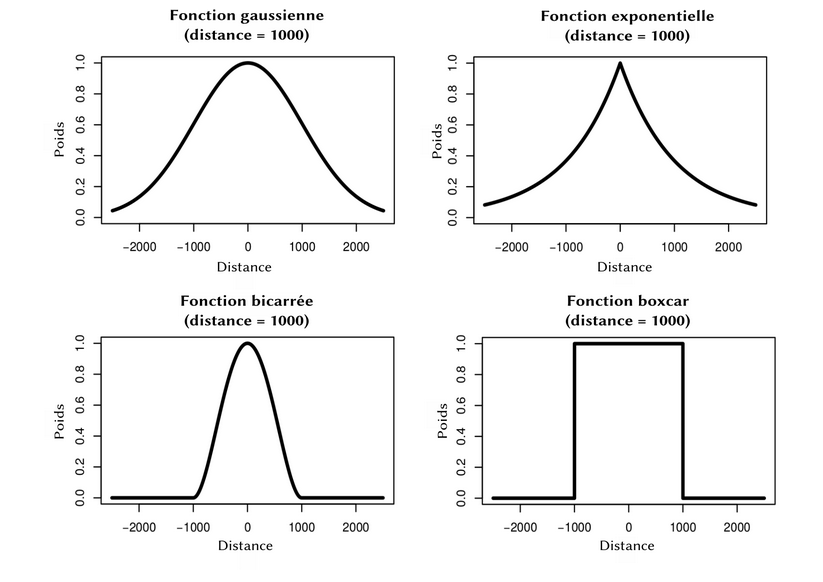
Définition de la bande passante avec R
# Définition de la bande passante (bandwidth en anglais)# Cette fonction n'est pas compatible avec le format sf il faut un Spatial DataFrame (contrairement à spgwr qui peut travailler avec un format sf)bw_g <-bw.gwr(data = sp_data_immo, approach ="AICc", kernel ="gaussian", adaptive =TRUE,dMat = dm.calib,formula = prix_med ~ perc_log_vac + perc_maison + perc_tiny_log + dens_pop + med_niveau_vis + part_log_suroccup + part_agri_nb_emploi + part_cadre_profintellec_nbemploi)
Adaptive bandwidth (number of nearest neighbours): 763 AICc value: 17959.04
Adaptive bandwidth (number of nearest neighbours): 480 AICc value: 17884.14
Adaptive bandwidth (number of nearest neighbours): 303 AICc value: 17798.07
Adaptive bandwidth (number of nearest neighbours): 196 AICc value: 17715.24
Adaptive bandwidth (number of nearest neighbours): 127 AICc value: 17622.76
Adaptive bandwidth (number of nearest neighbours): 87 AICc value: 17526.89
Adaptive bandwidth (number of nearest neighbours): 59 AICc value: 17422.28
Adaptive bandwidth (number of nearest neighbours): 45 AICc value: 17353.68
Adaptive bandwidth (number of nearest neighbours): 33 AICc value: 17283.09
Adaptive bandwidth (number of nearest neighbours): 29 AICc value: 17261.83
Adaptive bandwidth (number of nearest neighbours): 23 AICc value: 17250.23
Adaptive bandwidth (number of nearest neighbours): 22 AICc value: 17247.23
Adaptive bandwidth (number of nearest neighbours): 19 AICc value: 17201.79
Adaptive bandwidth (number of nearest neighbours): 19 AICc value: 17201.79
Estimation du modèle
Une fois la bande passante définie, on peut lancer l’estimation de notre modèle de GWR :
mod.gwr_g <-gwr.robust(data = sp_data_immo, dMat = dm.calib,bw = bw_g,kernel ="gaussian",filtered =FALSE, # un des problèmes de la GWR est de gérer des individus "aberrants" au niveau local. 2 méthodes ont été définies pour gérer cela. # Méthode 1 (argument TRUE) on filtre en fonction des individus standardisés. L'objectif est de détecter les individus dont les résidus sont très élevés et de les exclure.# Methode 2 (argument FALSE) on diminue le poids des observations aux résidus élevés.adaptive =TRUE,formula = prix_med ~ perc_log_vac + perc_maison + perc_tiny_log + dens_pop + med_niveau_vis + part_log_suroccup + part_agri_nb_emploi + part_cadre_profintellec_nbemploi)
Comparer les modèless
Si on souhaite comparer deux modèles car nous avons un doute sur les paramètres c’est tout à fait possible. Par exemple ici nous souhaitons comparer deux formes de noyaux.
Comme pour le modèle linéaire classique l’objet qui contient notre GWR est composé de plusieurs éléments. A la différence du modèle classique pour obtenir nos résultats il suffit d’appeler l’objet :
# Pour voir les différents éléments qui composent notre modèle de GWRsummary(mod.gwr_g)
Length Class Mode
GW.arguments 11 -none- list
GW.diagnostic 8 -none- list
lm 14 lm list
SDF 1223 SpatialPolygonsDataFrame S4
timings 5 -none- list
this.call 15 -none- call
Ftests 0 -none- list
Pour accéder aux résultats :
mod.gwr_g
***********************************************************************
* Package GWmodel *
***********************************************************************
Program starts at: 2026-02-27 19:41:28.175683
Call:
gwr.basic(formula = formula, data = data, bw = bw, kernel = kernel,
adaptive = adaptive, p = p, theta = theta, longlat = longlat,
dMat = dMat, F123.test = F123.test, cv = T, W.vect = W.vect,
parallel.method = parallel.method, parallel.arg = parallel.arg)
Dependent (y) variable: prix_med
Independent variables: perc_log_vac perc_maison perc_tiny_log dens_pop med_niveau_vis part_log_suroccup part_agri_nb_emploi part_cadre_profintellec_nbemploi
Number of data points: 1223
***********************************************************************
* Results of Global Regression *
***********************************************************************
Call:
lm(formula = formula, data = data)
Residuals:
Min 1Q Median 3Q Max
-1566.8 -220.2 -27.2 174.0 3277.3
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1592.873 11.204 142.171 < 2e-16 ***
perc_log_vac -287.337 14.134 -20.330 < 2e-16 ***
perc_maison -128.255 20.041 -6.400 2.22e-10 ***
perc_tiny_log -261.556 27.934 -9.363 < 2e-16 ***
dens_pop 173.942 15.272 11.389 < 2e-16 ***
med_niveau_vis 288.017 13.860 20.781 < 2e-16 ***
part_log_suroccup 388.982 27.352 14.221 < 2e-16 ***
part_agri_nb_emploi -20.785 15.059 -1.380 0.168
part_cadre_profintellec_nbemploi -7.841 19.904 -0.394 0.694
---Significance stars
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 391.8 on 1214 degrees of freedom
Multiple R-squared: 0.7784
Adjusted R-squared: 0.7769
F-statistic: 532.9 on 8 and 1214 DF, p-value: < 2.2e-16
***Extra Diagnostic information
Residual sum of squares: 186354789
Sigma(hat): 390.6721
AIC: 18086.13
AICc: 18086.31
BIC: 16985.31
***********************************************************************
* Results of Geographically Weighted Regression *
***********************************************************************
*********************Model calibration information*********************
Kernel function: gaussian
Adaptive bandwidth: 19 (number of nearest neighbours)
Regression points: the same locations as observations are used.
Distance metric: A distance matrix is specified for this model calibration.
****************Summary of GWR coefficient estimates:******************
Min. 1st Qu. Median
Intercept 1109.13394 1309.99018 1516.79508
perc_log_vac -919.82407 -224.60028 -163.40316
perc_maison -898.16365 -258.64481 -110.20592
perc_tiny_log -1210.96882 -206.68578 -92.91874
dens_pop -411.20172 72.82448 217.03593
med_niveau_vis 81.29015 287.78992 358.32914
part_log_suroccup -543.68600 42.42839 142.48859
part_agri_nb_emploi -498.74706 -65.81443 -32.88823
part_cadre_profintellec_nbemploi -347.37935 -48.57329 0.58811
3rd Qu. Max.
Intercept 1696.07367 2330.78
perc_log_vac -113.83881 388.64
perc_maison 76.01079 896.95
perc_tiny_log 32.81544 773.30
dens_pop 268.35651 659.84
med_niveau_vis 413.36560 853.98
part_log_suroccup 247.33650 700.50
part_agri_nb_emploi -1.15602 120.33
part_cadre_profintellec_nbemploi 49.93194 388.50
************************Diagnostic information*************************
Number of data points: 1223
Effective number of parameters (2trace(S) - trace(S'S)): 320.246
Effective degrees of freedom (n-2trace(S) + trace(S'S)): 902.754
AICc (GWR book, Fotheringham, et al. 2002, p. 61, eq 2.33): 17201.79
AIC (GWR book, Fotheringham, et al. 2002,GWR p. 96, eq. 4.22): 16849.26
BIC (GWR book, Fotheringham, et al. 2002,GWR p. 61, eq. 2.34): 17068.01
Residual sum of squares: 56808914
R-square value: 0.9324328
Adjusted R-square value: 0.9084372
***********************************************************************
Program stops at: 2026-02-27 19:41:39.380692
Visualiser les résultats
# Pour visualiser ce fichier dans R#View(mod.gwr_g$SDF@data)#Pour voir à quoi il ressemble de manière interactivedatatable(mod.gwr_g$SDF@data)
# Pour voir les variables qui le constituentnames(mod.gwr_g$SDF@data)
# On ajoute à data_immo les coefficientsdata_immo$agri.coef=mod.gwr_g$SDF$part_agri_nb_emploidata_immo$perc_maison.coef <- mod.gwr_g$SDF$perc_maisondata_immo$dens_pop.coef=mod.gwr_g$SDF$dens_popdata_immo$med_vie.coef=mod.gwr_g$SDF$med_niveau_visdata_immo$logvac.coef=mod.gwr_g$SDF$perc_log_vacdata_immo$tinylog.coef=mod.gwr_g$SDF$perc_tiny_logdata_immo$suroccup.coef=mod.gwr_g$SDF$part_log_suroccupdata_immo$cadre.coef=mod.gwr_g$SDF$part_cadre_profintellec_nbemploi# Réaliser la collection des cartespar(mfrow =c(2, 4))mf_map(x = data_immo, var ="agri.coef", type ="choro", pal="Earth")mf_title("Coefficients Agriculteurs")mf_map(x = data_immo, var ="perc_maison.coef", type ="choro", pal="Earth")mf_title("Coefficients de Maison")mf_map(x = data_immo, var ="dens_pop.coef", type ="choro", pal="Earth")mf_title("Coefficients de dens pop")mf_map(x = data_immo, var ="med_vie.coef", type ="choro", pal="Earth")mf_title("Coefficients de Médianne niveau de vie")mf_map(x = data_immo, var ="logvac.coef", type ="choro", pal="Earth")mf_title("Coefficients de Logements vacants")mf_map(x = data_immo, var ="tinylog.coef", type ="choro", pal="Earth")mf_title("Coefficients de Petits logements")mf_map(x = data_immo, var ="suroccup.coef", type ="choro", pal="Earth")mf_title("Coefficients de logement suroocupés")mf_map(x = data_immo, var ="cadre.coef", type ="choro", pal="Earth")mf_title("Coefficients de Cadre")
Contribution max
data_immo$agri.t <- mod.gwr_g$SDF$part_agri_nb_emploi_TVdata_immo$maison.t <- mod.gwr_g$SDF$perc_maison_TVdata_immo$dens.t <- mod.gwr_g$SDF$dens_pop_TVdata_immo$medvie.t <- mod.gwr_g$SDF$med_niveau_vis_TVdata_immo$logvac.t <- mod.gwr_g$SDF$perc_log_vac_TVdata_immo$tinylog.t <- mod.gwr_g$SDF$perc_tiny_log_TVdata_immo$suroccup.t <- mod.gwr_g$SDF$part_log_suroccup_TVdata_immo$cadre.t <- mod.gwr_g$SDF$part_cadre_profintellec_nbemploi_TV #Définir contrib maxdf<-as.data.frame(data_immo)# On passe les t-values en valeurs absolues pour voir la plus grande contribution dans un sens sens ou dans l'autredata_immo$contribmax<-colnames(df[, c(30:37)])[max.col(abs(df[, c(30:37)]),ties.method="first")]par(mfrow =c(1, 1))# Cartemf_map(x = data_immo, var ="contribmax", type ="typo", pal="Zissou 1")mf_title("Carte des variables contribuant le plus par epci")
Cartographier les R2
data_immo$r2local=mod.gwr_g$SDF$Local_R2mf_map(x = data_immo, var ="r2local", type ="choro", pal="Reds")mf_title("R2 Locaux")
Les t-value et p-value
# Pour rappel si on a plus de 200 individus et le t-value > |1.96| on pourra considérer le coefficient comme significatif au seuil de 0.05 (95% chances que ce ne soit pas dû au hasard)data_immo$nbsignif_t<-rowSums(abs(df[, c(30:37)]) >1.96)mf_map(x = data_immo, var ="nbsignif_t", type ="typo", pal="Reds")mf_title("Nombre des Betas significatif par EPCI (t-value)")
# Les p-value ne sont pas fournit dans le modèle de la GWR, on pourrait les calculer à partir de t-value et de l'erreur standard mais le package GWmodel propose une fonction pour les obttenirpvalue<-gwr.t.adjust(mod.gwr_g)# On ajoute les p-value à notre fichierdata_immo$agri.p <- pvalue$SDF$part_agri_nb_emploi_p data_immo$maison.p <- pvalue$SDF$perc_maison_pdata_immo$dens.p <- pvalue$SDF$dens_pop_pdata_immo$medvie.p <- pvalue$SDF$med_niveau_vis_pdata_immo$logvac.p <- pvalue$SDF$perc_log_vac_pdata_immo$tinylog.p <- pvalue$SDF$perc_tiny_log_pdata_immo$suroccup.p <- pvalue$SDF$part_log_suroccup_pdata_immo$cadre.p <- pvalue$SDF$part_cadre_profintellec_nbemploi_pdf<-as.data.frame(data_immo)data_immo$nbsignif_p<-rowSums(df[, c(41:48)] <0.05)mf_map(x = data_immo, var ="nbsignif_p", type ="typo", pal="Reds")
P-value par variable
# Ici nous représenterons les p-value avec un decoupage par classe de significativité et seulement les p-value de 2 VIpar(mfrow =c(1, 2))# Par exemple les p-value des coefficients de la variable part de l'emploi agriculteurdata_immo<- data_immo %>%mutate(agri.p_fac =case_when(agri.p <=0.002~"[0;0.002[", agri.p <=0.01~"[0.002;0.01[", agri.p <=0.05~"[0.01;0.05[", agri.p <=0.1~"[0.05;0.1[",TRUE~"[0.1;1]")) %>%mutate(agri.p_fac =factor(agri.p_fac,levels =c("[0;0.002[", "[0.002;0.01[","[0.01;0.05[","[0.05;0.1[", "[0.1;1]")))mypal2 <-mf_get_pal(n =5, palette ="SunsetDark")mf_map(x = data_immo, var ="agri.p_fac", type ="typo", border ="grey3", lwd =0.1, pal=mypal2, leg_title ="Classe P-value")mf_title("P-value du coefficient de la part d'emploi agriculteurs")# Pour la densité de populationdata_immo<- data_immo %>%mutate(dens.p_fac =case_when(dens.p<=0.002~"[0;0.002[", dens.p <=0.01~"[0.002;0.01[", dens.p <=0.05~"[0.01;0.05[", dens.p <=0.1~"[0.05;0.1[",TRUE~"[0.1;1]")) %>%mutate(dens.p_fac =factor(dens.p_fac,levels =c("[0;0.002[", "[0.002;0.01[","[0.01;0.05[","[0.05;0.1[", "[0.1;1]")))mf_map(x = data_immo, var ="dens.p_fac", type ="typo", border ="grey3", lwd =0.1, pal=mypal2, leg_title ="Classe P-value")mf_title("P-value du coefficient de la densité de population")
VIII. Extensions de la GWR
MGWR : Multiscale GWR
Idée : différentes variables peuvent varier à différentes échelles






























Comment la statistique spatiale répond
Pour l’autocorrélation :
Pour la non-stationnarité :